3.1. Librería Pandas¶
Nota
Propósito: es una libraría usada en el manejo y análisis de estructuras de datos.
Pandas es una librería de Python especializada en el manejo y análisis de estructuras de datos, que proporciona unas estructuras de datos flexibles y que permiten trabajar con ellos de forma muy eficiente.
Figura 3.1, Logotipo de librería Pandas¶
Las principales características de esta librería son:
Define nuevas estructuras de datos basadas en los arrays de la librería NumPy pero con nuevas funcionalidades.
Permite leer y escribir fácilmente ficheros en formato CSV, Excel y bases de datos SQL.
Permite acceder a los datos mediante índices o nombres para filas y columnas.
Ofrece métodos para reordenar, dividir y combinar conjuntos de datos.
Permite trabajar con series temporales.
Realiza todas estas operaciones de manera muy eficiente.
3.1.1. Instalación¶
Para instalar el paquete pandas ejecute el siguiente comando, el cual a continuación se presentan el correspondiente comando de tu sistema operativo:
pip3 install pandas
pip install pandas
Puede probar si la instalación se realizo correctamente, ejecutando el siguiente comando correspondiente a tu sistema operativo:
python3 -c "import pandas ; print(pandas.__version__)"
python -c "import pandas ; print(pandas.__version__)"
Si muestra el numero de la versión instalada de pandas, tiene correctamente
instalada la paquete. Con esto, ya tiene todo listo para continuar.
3.1.2. Tipos de datos de Pandas¶
Pandas dispone de tres estructuras de datos diferentes:
Series: Estructura de una dimensión.
DataFrame: Estructura de dos dimensiones (tablas).
Panel: Estructura de tres dimensiones (cubos).
Estas estructuras se construyen a partir de arrays de la librería NumPy, añadiendo nuevas funcionalidades.
3.1.3. Clase Series¶
Son estructuras similares a los arrays de una dimensión. Son homogéneas, es decir, sus elementos tienen que ser del mismo tipo, y su tamaño es inmutable, es decir, no se puede cambiar, aunque si su contenido.
Dispone de un índice que asocia un nombre a cada elemento del la serie, a través de la cuál se accede al elemento.
Ejemplo. La siguiente serie contiene las asignaturas de un curso.

Figura 3.2, Ejemplo de Clase series¶
3.1.4. Creación de series¶
3.1.4.1. Crear serie desde lista¶
Series(data=lista, index=indices, dtype=tipo): Devuelve un objeto de tipo Series con los datos de la listalista, las filas especificados en la listaindicesy el tipo de datos indicado entipo. Si no se pasa la lista de índices se utilizan como índices los enteros del 0 al $n-1$, done $n$ es el tamaño de la serie. Si no se pasa el tipo de dato se infiere.
1 2 3 4 5 6 7 8 9 10 11 | |
3.1.4.2. Crear serie desde diccionario¶
Series(data=diccionario, index=indices): Devuelve un objeto de tipo Series con los valores del diccionariodiccionarioy las filas especificados en la listaindices. Si no se pasa la lista de índices se utilizan como índices las claves del diccionario.
1 2 3 4 5 6 7 | |
3.1.5. Atributos de serie¶
Existen varias propiedades o métodos para ver las características de una serie.
s.size: Devuelve el número de elementos de la series.s.index: Devuelve una lista con los nombres de las filas del DataFrames.s.dtype: Devuelve el tipo de datos de los elementos de la series.
1 2 3 4 5 6 7 8 | |
3.1.6. Acceso a los elementos de serie¶
El acceso a los elementos de un objeto del tipo Series puede ser a través de posiciones o través de índices (nombres).
3.1.6.1. Acceso por posición¶
Se realiza de forma similar a como se accede a los elementos de un array.
s[i]: Devuelve el elemento que ocupa la posicióni+1en la series.s[posiciones]: Devuelve otra serie con los elementos que ocupan las posiciones de la listaposiciones.
3.1.6.2. Acceso por índice¶
s[nombre]: Devuelve el elemento con el nombrenombreen el índice.s[nombres]: Devuelve otra serie con los elementos correspondientes a los nombres indicadas en la listanombresen el índice.
1 2 3 4 5 6 7 8 9 10 | |
3.1.7. Resumen descriptivo de serie¶
Las siguientes funciones permiten resumir varios aspectos de una serie:
s.count(): Devuelve el número de elementos que no son nulos niNaNen la series.s.sum(): Devuelve la suma de los datos de la seriescuando los datos son de un tipo numérico, o la concatenación de ellos cuando son del tipo cadenastr.s.cumsum()Devuelve una serie con la sumaacumulada de los datos de la serie
scuando los datos son de un tipo numérico.
s.value_counts(): Devuelve una serie con la frecuencia (número de repeticiones) de cada valor de la series.s.min(): Devuelve el menor de los datos de la series.s.max(): Devuelve el mayor de los datos de la series.s.mean(): Devuelve la media de los datos de la seriescuando los datos son de un tipo numérico.s.var(): Devuelve la varianza de los datos de la seriescuando los datos son de un tipo numérico.s.std(): Devuelve la desviación típica de los datos de la seriescuando los datos son de un tipo numérico.s.describe(): Devuelve una serie con un resumen descriptivo que incluye el número de datos, su suma, el mínimo, el máximo, la media, la desviación típica y los cuartiles.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | |
3.1.8. Aplicar operaciones a serie¶
Los operadores binarios (+, *, /, etc.) pueden utilizarse con una serie,
y devuelven otra serie con el resultado de aplicar la operación a cada elemento de la
serie.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
3.1.9. Aplicar funciones a serie¶
También es posible aplicar una función a cada elemento de la serie mediante el siguiente método:
s.apply(f): Devuelve una serie con el resultado de aplicar la funciónfa cada uno de los elementos de la series.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
3.1.10. Filtrar serie¶
Para filtrar una serie y quedarse con los valores que cumplen una determinada condición se utiliza el siguiente método:
s[condicion]: Devuelve una serie con los elementos de la seriesque se corresponden con el valorTruede la lista booleanacondicion.condiciondebe ser una lista de valores booleanos de la misma longitud que la serie.
1 2 3 4 5 6 | |
3.1.11. Ordenar serie¶
Para ordenar una serie se utilizan los siguientes métodos:
s.sort_values(ascending=booleano) : Devuelve la serie que resulta de ordenar los valores la series. Si argumento del parámetroascendingesTrueel orden es creciente y si esFalsedecreciente.df.sort_index(ascending=booleano) : Devuelve la serie que resulta de ordenar el índice de la series. Si el argumento del parámetroascendingesTrueel orden es creciente y si esFalsedecreciente.
1 2 3 4 5 6 7 8 9 10 11 12 | |
3.1.12. Eliminar los datos desconocidos en serie¶
Los datos desconocidos representan en Pandas por NaN y los nulos por
None. Tanto unos como otros suelen ser un problema a la hora de realizar
algunos análisis de datos, por lo que es habitual eliminarlos. Para eliminarlos
de una serie se utiliza el siguiente método:
s.dropna(): Elimina los datos desconocidos o nulos de la series.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
3.1.13. Clase DataFrame¶
Un objeto del tipo DataFrame define un conjunto de datos estructurado en forma
de tabla donde cada columna es un objeto de tipo Series, es decir, todos los
datos de una misma columna son del mismo tipo, y las filas son registros que
pueden contender datos de distintos tipos.
Un DataFrame contiene dos índices, uno para las filas y otro para las columnas,
y se puede acceder a sus elementos mediante los nombres de las filas y las
columnas.
Ejemplo. El siguiente DataFrame contiene información sobre los alumnos
de un curso. Cada fila corresponde a un alumno y cada columna a una variable.
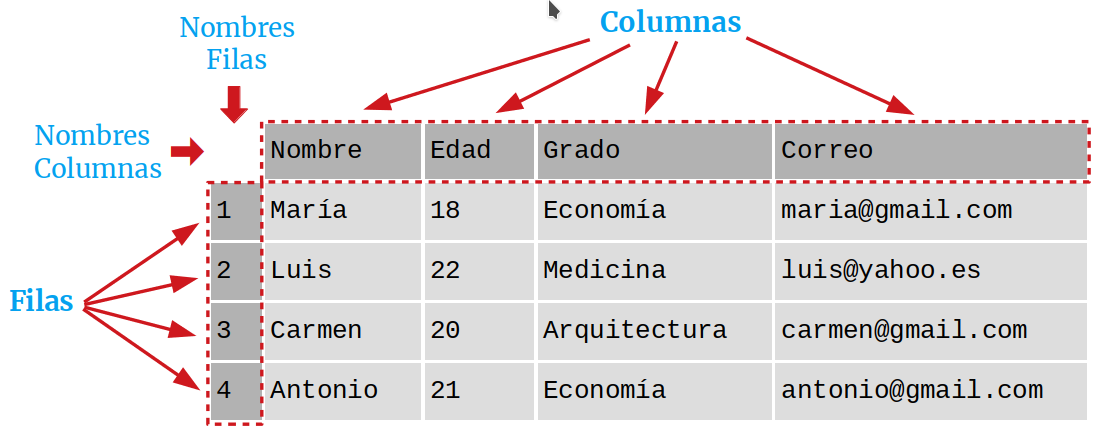
Figura 3.3, Ejemplo de DataFrame¶
3.1.14. Creación de DataFrame¶
3.1.14.1. Crear DataFrame desde diccionario de listas¶
Para crear un DataFrame a partir de un diccionario cuyas claves son los nombres de las columnas y los valores son listas con los datos de las columnas se utiliza el método:
DataFrame(data=diccionario, index=filas, columns=columnas, dtype=tipos): Devuelve un objeto del tipo DataFrame cuyas columnas son las listas contenidas en los valores del diccionariodiccionario, los nombres de filas indicados en la listafilas, los nombres de columnas indicados en la listacolumnasy los tipos indicados en la listatipos. La listafilastiene que tener el mismo tamaño que las listas del diccionario, mientras que las listascolumnasytipostienen que tener el mismo tamaño que el diccionario. Si no se pasa la lista de filas se utilizan como nombres los enteros empezando en 0. Si no se pasa la lista de columnas se utilizan como nombres las claves del diccionario. Si no se pasa la lista de tipos, se infiere.
Los valores asociados a las claves del diccionario deben ser listas del mismo tamaño.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
3.1.14.2. Crear DataFrame desde lista de listas¶
Para crear un DataFrame a partir de una lista de listas con los datos de las columnas se utiliza el siguiente método:
DataFrame(data=listas, index=filas, columns=columnas, dtype=tipos): Devuelve un objeto del tipo DataFrame cuyas columnas son los valores de las listas de la listalistas, los nombres de filas indicados en la listafilas, los nombres de columnas indicados en la listacolumnasy los tipos indicados en la listatipos. La listafilas, tiene que tener el mismo tamaño que la listalistasmientras que las listascolumnasytipostienen que tener el mismo tamaño que las listas anidadas enlistas. Si no se pasa la lista de filas o de columnas se utilizan enteros empezando en 0. Si no se pasa la lista de tipos, se infiere.
Si las listas anidadas en listas no tienen el mismo tamaño, las listas menores
se rellenan con valores NaN.
1 2 3 4 5 6 7 8 9 | |
3.1.14.3. Crear DataFrame desde lista de diccionarios¶
Para crear un DataFrame a partir de una lista de diccionarios con los datos de las filas, se utiliza el siguiente método:
DataFrame(data=diccionarios, index=filas, columns=columnas, dtype=tipos): Devuelve un objeto del tipo DataFrame cuyas filas contienen los valores de los diccionarios de la listadiccionarios, los nombres de filas indicados en la listafilas, los nombres de columnas indicados en la listacolumnasy los tipos indicados en la listatipos. La listafilastiene que tener el mismo tamaño que la listalista. Si no se pasa la lista de filas se utilizan enteros empezando en 0. Si no se pasa la lista de columnas se utilizan las claves de los diccionarios. Si no se pasa la lista de tipos, se infiere.
Si los diccionarios no tienen las mismas claves, las claves que no
aparecen en el diccionario se rellenan con valores NaN.
1 2 3 4 5 6 7 8 9 10 11 12 | |
3.1.14.4. Crear DataFrame desde array¶
Para crear un DataFrame a partir de un array de NumPy se utiliza el siguiente método:
DataFrame(data=array, index=filas, columns=columnas, dtype=tipo): Devuelve un objeto del tipo DataFrame cuyas filas y columnas son las del arrayarray, los nombres de filas indicados en la listafilas, los nombres de columnas indicados en la listacolumnasy el tipo indicado entipo. La listafilastiene que tener el mismo tamaño que el número de filas del array y la listacolumnasel mismo tamaño que el número de columnas del array. Si no se pasa la lista de filas se utilizan enteros empezando en 0. Si no se pasa la lista de columnas se utilizan las claves de los diccionarios. Si no se pasa la lista de tipos, se infiere.
1 2 3 4 5 6 7 8 | |
3.1.14.5. Crear DataFrame desde hoja de calculo¶
Dependiendo del tipo de fichero (CSV o Excel), existen distintas funciones para importar un DataFrame desde un fichero.
read_csv(fichero.csv, sep=separador, header=n, index_col=m, na_values=no-validos, decimal=separador-decimal): Devuelve un objeto del tipo DataFrame con los datos del fichero CSVfichero.csvusando como separador de los datos la cadenaseparador. Como nombres de columnas se utiliza los valores de la filany como nombres de filas los valores de la columnam. Si no se indicamse utilizan como nombres de filas los enteros empezando en 0. Los valores incluidos en la listano-validosse convierten enNaN. Para los datos numéricos se utiliza como separador de decimales el carácter indicado enseparador-decimal.read_excel(fichero.xlsx, sheet_name=hoja, header=n, index_col=m, na_values=no-validos, decimal=separador-decimal): Devuelve un objeto del tipo DataFrame con los datos de la hoja de cálculohojadel fichero Excelfichero.xlsx. Como nombres de columnas se utiliza los valores de la filany como nombres de filas los valores de la columnam. Si no se indicamse utilizan como nombres de filas los enteros empezando en 0. Los valores incluidos en la listano-validosse convierten enNaN. Para los datos numéricos se utiliza como separador de decimales el carácter indicado enseparador-decimal.1 2 3 4 5 6 7 8 9 10 11 12 13 14
>>> import pandas as pd >>> # Importación del fichero datos-colesteroles.csv >>> df = pd.read_csv( ... "https://raw.githubusercontent.com/macagua/entrenamiento.data_scientist_python/main/recursos/leccion3/datos/colesteroles.csv", ... sep=";", ... decimal=",", ... ) >>> print(df.head()) nombre edad sexo peso altura colesterol 0 José Luis Martínez Izquierdo 18 H 85.0 1.79 182.0 1 Rosa Díaz Díaz 32 M 65.0 1.73 232.0 2 Javier García Sánchez 24 H NaN 1.81 191.0 3 Carmen López Pinzón 35 M 65.0 1.70 200.0 4 Marisa López Collado 46 M 51.0 1.58 148.0
3.1.15. Exportación de ficheros¶
También existen funciones para exportar un DataFrame a un fichero con diferentes formatos.
df.to_csv(fichero.csv, sep=separador, columns=booleano, index=booleano): Exporta el DataFramedfal ficherofichero.csven formato CSV usando como separador de los datos la cadenaseparador. Si se pasaTrueal parámetrocolumnsse exporta también la fila con los nombres de columnas y si se pasaTrueal parámetroindexse exporta también la columna con los nombres de las filas.df.to_excel(fichero.xlsx, sheet_name = hoja, columns=booleano, index=booleano): Exporta el DataFramedfa la hoja de cálculohojadel ficherofichero.xlsxen formato Excel. Si se pasaTrueal parámetrocolumnsse exporta también la fila con los nombres de columnas y si se pasaTrueal parámetroindexse exporta también la columna con los nombres de las filas.
3.1.16. Atributos de DataFrame¶
Existen varias propiedades o métodos para ver las características de un DataFrame.
df.info(): Devuelve información (número de filas, número de columnas, índices, tipo de las columnas y memoria usado) sobre el DataFramedf.df.shape: Devuelve una tupla con el número de filas y columnas del DataFramedf.df.size: Devuelve el número de elementos del DataFrame.df.columns: Devuelve una lista con los nombres de las columnas del DataFramedf.df.index: Devuelve una lista con los nombres de las filas del DataFramedf.df.dtypes: Devuelve una serie con los tipos de datos de las columnas del DataFramedf.df.head(n): Devuelve lasnprimeras filas del DataFramedf.df.tail(n): Devuelve lasnúltimas filas del DataFramedf.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | |
3.1.17. Renombrar los nombres de las filas y columnas¶
Para cambiar el nombre de las filas y las columnas de un DataFrame se utiliza el siguiente método:
df.rename(columns=columnas, index=filas): Devuelve el DataFrame que resulta de renombrar las columnas indicadas en las claves del diccionariocolumnascon sus valores y las filas indicadas en las claves del diccionariofilascon sus valores en el DataFramedf.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
3.1.18. Cambiar el índice de DataFrame¶
Aunque el índice de un DataFrame suele fijarse en la creación del mismo, en ocasiones puede ser necesario cambiar el índice una vez creado el DataFrame. Para ello se utiliza el siguiente método:
df.set_index(keys = columnas, verify_integrity = bool): Devuelve el DataFrame que resulta de eliminar las columnas de la listacolumnasy convertirlas en el nuevo índice. El parámetroverify_integrityrecibe un booleano (Falsepor defecto) y realiza una comprobación para evitar duplicados en la clave cuando recibeTrue.
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
3.1.19. Reindexar DataFrame¶
Para reordenar los índices de las filas y las columnas de un DataFrame, así como añadir o eliminar índices, se utiliza el siguiente método:
df.reindex(index=filas, columns=columnas, fill_value=relleno): Devuelve el DataFrame que resulta de tomar del DataFramedflas filas con nombres en la listafilasy las columnas con nombres en la listacolumnas. Si alguno de los nombres indicados enfilasocolumnasno existía en el DataFramedf, se crean filan o columnas nuevas rellenas con el valorrelleno.
1 2 3 4 5 6 7 8 9 | |
3.1.20. Acceso a los elementos de DataFrame¶
El acceso a los datos de un DataFrame se puede hacer a través de posiciones o través de los nombres de las filas y columnas.
3.1.20.1. Accesos mediante posiciones¶
df.iloc[i, j]: Devuelve el elemento que se encuentra en la filaiy la columnajdel DataFramedf. Pueden indicarse secuencias de índices para obtener partes del DataFrame.df.iloc[filas, columnas]: Devuelve un DataFrame con los elementos de las filas de la listafilasy de las columnas de la listacolumnas.df.iloc[i]: Devuelve una serie con los elementos de la filaidel DataFramedf.
1 2 3 4 5 6 7 8 9 | |
3.1.20.2. Acceso a los elementos mediante nombres¶
df.loc[fila, columna]Devuelve el elementoque se encuentra en la fila con nombre
filay la columna de con nombrecolumnadel DataFramedf.
df.loc[filas, columnas]Devuelve un DataFramecon los elemento que se encuentra en las filas con los nombres de la lista
filasy las columnas con los nombres de la listacolumnasdel DataFramedf.
df[columna]Devuelve una serie con loselementos de la columna de nombre
columnadel DataFramedf.
df.columnaDevuelve una serie con loselementos de la columna de nombre
columnadel DataFramedf. Es similar al método anterior pero solo funciona cuando el nombre de la columna no tiene espacios en blanco.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
3.1.21. Operaciones con columnas de DataFrame¶
3.1.21.1. Añadir columnas a DataFrame¶
El procedimiento para añadir una nueva columna a un DataFrame es similar al de añadir un nuevo par a un diccionario, pero pasando los valores de la columna en una lista o serie.
d[nombre] = lista: Añade al DataFramedfuna nueva columna con el nombrenombrey los valores de la listalista. La lista debe tener el mismo tamaño que el número de filas dedf.d[nombre] = serie: Añade al DataFramedfuna nueva columna con el nombrenombrey los valores de la serieserie. Si el tamaño de la serie es menor que el número de filas dedfse rellena con valoresNaNmientras que si es mayor se recorta.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
3.1.21.2. Operaciones sobre columnas¶
Puesto que los datos de una misma columna de un DataFrame son del mismo tipo, es fácil aplicar la misma operación a todos los elementos de la columna.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
3.1.21.3. Aplicar funciones a columnas¶
Para aplicar funciones a todos los elementos de una columna se utiliza el siguiente método:
df[columna].apply(f): Devuelve una serie con los valores que resulta de aplicar la funciónfa los elementos de la columna con nombrecolumnadel DataFramedf.
1 2 3 4 5 6 7 8 9 10 | |
3.1.21.4. Convertir una columna al tipo datetime¶
A menudo una columna contiene cadenas que representan fechas. Para
convertir estas cadenas al tipo datetime se utiliza el siguiente
método:
to_datetime(columna, formato): Devuelve la serie que resulta de convertir las cadenas de la columna con el nombrecolumnaen fechas del tipodatetimecon el formado especificado enformato.Truco
Para más información consulte la documentación oficial de datetime.
1 2 3 4 5 6 7 8 9 10 11 12 | |
3.1.21.5. Resumen descriptivo de DataFrame¶
Al igual que para las series, los siguientes métodos permiten resumir la información de un DataFrame por columnas:
df.count(): Devuelve una serie con el número de elementos que no son nulos niNaNen cada columna del DataFramedf.df.sum(): Devuelve una serie con la suma de los datos de las columnas del DataFramedfcuando los datos son de un tipo numérico, o la concatenación de ellos cuando son del tipo cadenastr.df.cumsum(): Devuelve un DataFrame con la suma acumulada de los datos de las columnas del DataFramedfcuando los datos son de un tipo numérico.df.min(): Devuelve una serie con los menores de los datos de las columnas del DataFramedf.df.max(): Devuelve una serie con los mayores de los datos de las columnas del DataFramedf.df.mean(): Devuelve una serie con las medias de los datos de las columnas numéricas del DataFramedf.df.var(): Devuelve una serie con las varianzas de los datos de las columnas numéricas del DataFramedf.df.std(): Devuelve una serie con las desviaciones típicas de los datos de las columnas numéricas del DataFramedf.df.cov(): Devuelve un DataFrame con las covarianzas de los datos de las columnas numéricas del DataFramedf.df.corr(): Devuelve un DataFrame con los coeficientes de correlación de Pearson de los datos de las columnas numéricas del DataFramedf.df.describe(include = tipo): Devuelve un DataFrame con un resumen estadístico de las columnas del DataFramedfdel tipotipo. Para los datos numéricos (number) se calcula la media, la desviación típica, el mínimo, el máximo y los cuartiles. Para los datos no numéricos (object) se calcula el número de valores, el número de valores distintos, la moda y su frecuencia. Si no se indica el tipo solo se consideran las columnas numéricas.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | |
3.1.21.6. Eliminar columnas de DataFrame¶
Para eliminar columnas de un DataFrame se utilizan los siguientes métodos:
del d[nombre]: Elimina la columna con nombrenombredel DataFramedf.df.pop(nombre): Elimina la columna con nombrenombredel DataFramedfy la devuelve como una serie.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
3.1.22. Operaciones con las filas de DataFrame¶
3.1.22.1. Añadir una fila a DataFrame¶
Para añadir una fila a un DataFrame se utiliza el siguiente método:
df.append(serie, ignore_index=True): Devuelve el DataFrame que resulta de añadir una fila al DataFramedfcon los valores de la serieserie. Los nombres del índice de la serie deben corresponderse con los nombres de las columnas dedf. Si no se pasa el parámetroignore_indexentonces debe pasarse el parámetronamea la serie, donde su argumento será el nombre de la nueva fila.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
3.1.22.2. Eliminar filas de DataFrame¶
Para eliminar filas de un DataFrame se utilizan el siguiente método:
df.drop(filas): Devuelve el DataFrame que resulta de eliminar las filas con los nombres indicados en la listafilasdel DataFramedf.
1 2 3 4 5 6 7 8 9 10 | |
3.1.22.3. Filtrar las filas de DataFrame¶
Una operación bastante común con un DataFrame es obtener las filas que cumplen una determinada condición.
df[condicion]: Devuelve un DataFrame con las filas del DataFramedfque se corresponden con el valorTruede la lista booleanacondicion.condiciondebe ser una lista de valores booleanos de la misma longitud que el número de filas del DataFrame.
1 2 3 4 5 6 7 8 | |
3.1.22.4. Ordenar DataFrame¶
Para ordenar un DataFrame de acuerdo a los valores de una determinada columna se utilizan los siguientes métodos:
df.sort_values(columna, ascending=booleano) : Devuelve el DataFrame que resulta de ordenar las filas del DataFramedfsegún los valores del la columna con nombrecolumna. Si argumento del parámetroascendingesTrueel orden es creciente y si esFalsedecreciente.df.sort_index(ascending=booleano) : Devuelve el DataFrame que resulta de ordenar las filas del DataFramedfsegún los nombres de las filas. Si el argumento del parámetroascendingesTrueel orden es creciente y si esFalsedecreciente.
1 2 3 4 5 6 7 8 9 10 11 | |
3.1.22.5. Eliminar las filas con datos desconocidos en DataFrame¶
Para eliminar las filas de un DataFrame que contienen datos desconocidos NaN
o nulos None se utiliza el siguiente método:
s.dropna(subset=columnas): Devuelve el DataFrame que resulta de eliminar las filas que contienen algún dato desconocido o nulo en las columnas de la listacolumnadel DataFramedf. Si no se pasa un argumento al parámetrosubsetse aplica a todas las columnas del DataFrame.
1 2 3 4 5 6 7 8 9 10 11 | |
3.1.23. Agrupación de DataFrame¶
En muchas aplicaciones es útil agrupar los datos de un DataFrame de acuerdo a los valores de una o varias columnas (categorías), como por ejemplo el sexo o el país.
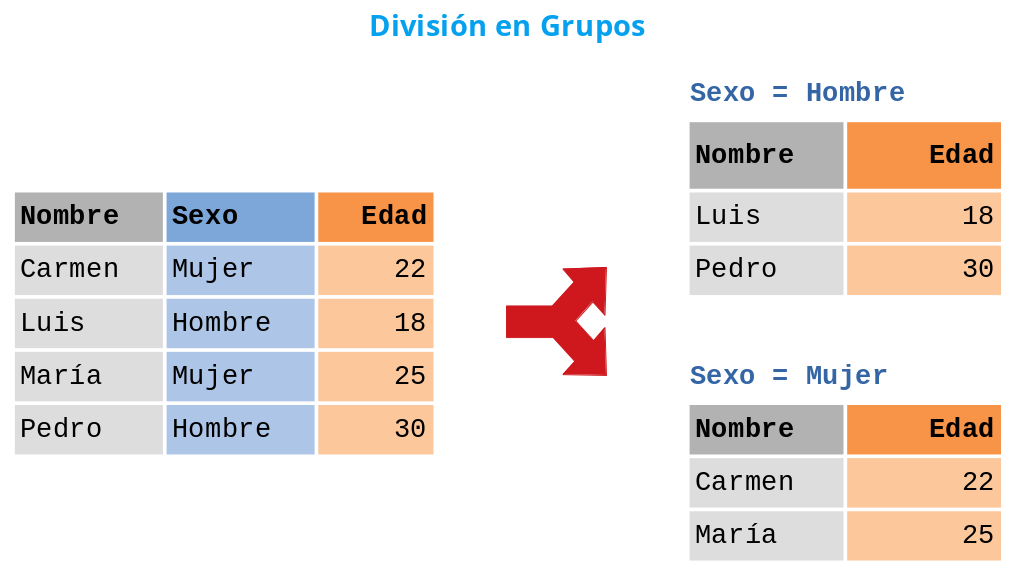
Figura 3.4, División en grupos de un DataFrame¶
3.1.23.1. Dividir DataFrame en grupos¶
Para dividir un DataFrame en grupos se utiliza el siguiente método:
df.groupby(columnas).groups: Devuelve un diccionario con cuyas claves son las tuplas que resultan de todas las combinaciones de los valores de las columnas con nombres en la listacolumnas, y valores las listas de los nombres de las filas que contienen esos valores en las correspondientes columnas del DataFramedf.
1 2 3 4 5 6 7 8 | |
Para obtener un grupo concreto se utiliza el siguiente método:
df.groupby(columnas).get_group(valores): Devuelve un DataFrame con las filas del DataFramedfque cumplen que las columnas de la listacolumnaspresentan los valores de la tuplavalores. La listacolumnasy la tuplavaloresdeben tener el mismo tamaño.
1 2 3 4 5 6 7 8 9 10 11 12 | |
3.1.23.2. Aplicar una función de agregación por grupos¶
Una vez dividido el DataFame en grupos, es posible aplicar funciones de agregación a cada grupo mediante el siguiente método:
df.groupby(columnas).agg(funciones): Devuelve un DataFrame con el resultado de aplicar las funciones de agregación de la listafuncionesa cada uno de los DataFrames que resultan de dividir el DataFrame según las columnas de la listacolumnas.
Una función de agregación toma como argumento una lista y devuelve una único valor. Algunas de las funciones de agregación más comunes son:
np.min: Devuelve el mínimo de una lista de valores.np.max: Devuelve el máximo de una lista de valores.np.count_nonzero: Devuelve el número de valores no nulos de una lista de valores.np.sum: Devuelve la suma de una lista de valores.np.mean: Devuelve la media de una lista de valores.np.std: Devuelve la desviación típica de una lista de valores.
1 2 3 4 5 6 7 8 9 | |
3.1.24. Reestructurar DataFrame¶
A menudo la disposición de los datos en un DataFrame no es la adecuada para su tratamiento y es necesario reestructurar el DataFrame. Los datos que contiene un DataFrame pueden organizarse en dos formatos: ancho y largo.
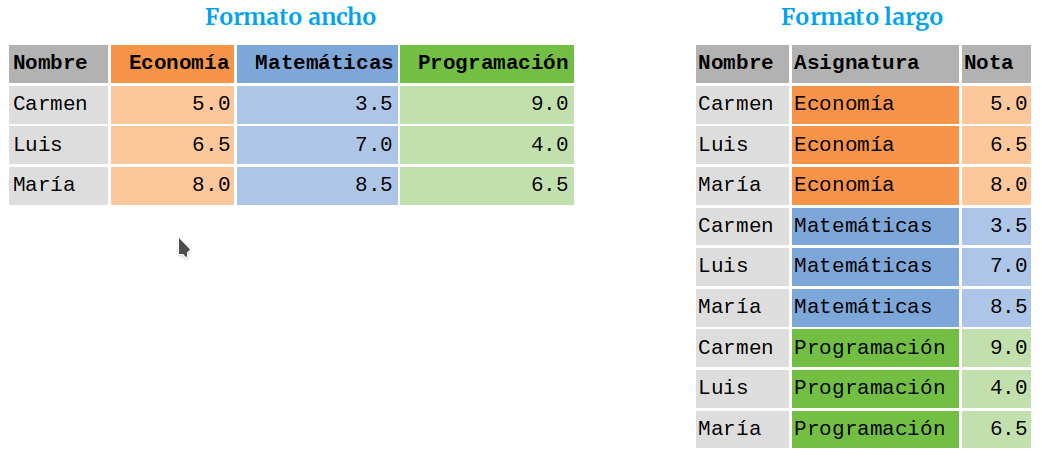
Figura 3.5, Formatos de un DataFrame¶
3.1.24.1. Convertir DataFrame a formato largo¶
Para convertir un DataFrame de formato ancho a formato largo (columnas a filas) se utiliza el siguiente método:
df.melt(id_vars=id-columnas, value_vars=columnas, var_name=nombre-columnas, var_value=nombre-valores): Devuelve el DataFrame que resulta de convertir el DataFramedfde formato ancho a formato largo. Todas las columnas de listacolumnasse reestructuran en dos nuevas columnas con nombresnombre-columnasynombre-valoresque contienen los nombres de las columnas originales y sus valores, respectivamente. Las columnas en la listaid-columnasse mantienen sin reestructurar. Si no se pasa la listacolumnasentonces se reestructuran todas las columnas excepto las columnas de la listaid-columnas.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
3.1.24.2. Convertir DataFrame a formato ancho¶
Para convertir un DataFrame de formato largo a formato ancho (filas a columnas) se utiliza el siguiente método:
df.pivot(index=filas, columns=columna, values=valores): Devuelve el DataFrame que resulta de convertir el DataFramedfde formato largo a formato ancho. Se crean tantas columnas nuevas como valores distintos haya en la columnacolumna. Los nombres de estas nuevas columnas son los valores de la columnacolumnamientras que sus valores se toman de la columnavalores. Los nombres del índice del nuevo DataFrame se toman de los valores de la columnafilas.
1 2 3 4 5 6 7 | |
3.1.25. Combinar varios DataFrames¶
Dos o más DataFrames pueden combinarse en otro DataFrame. La combinación puede ser de varias formas:
Concatenación: Combinación de varios DataFrames concatenando sus filas o columnas.
Mezcla: Combinación de varios DataFrames usando columnas o índices comunes.
3.1.25.1. Concatenación de DataFrames¶
Concatenación de filas. Las filas de los DataFrames se concatenan unas a continuación de las otras para formar el nuevo DataFrame. Para ello es necesario que los DataFrames que se combinen tengan el mismo índice de columnas.
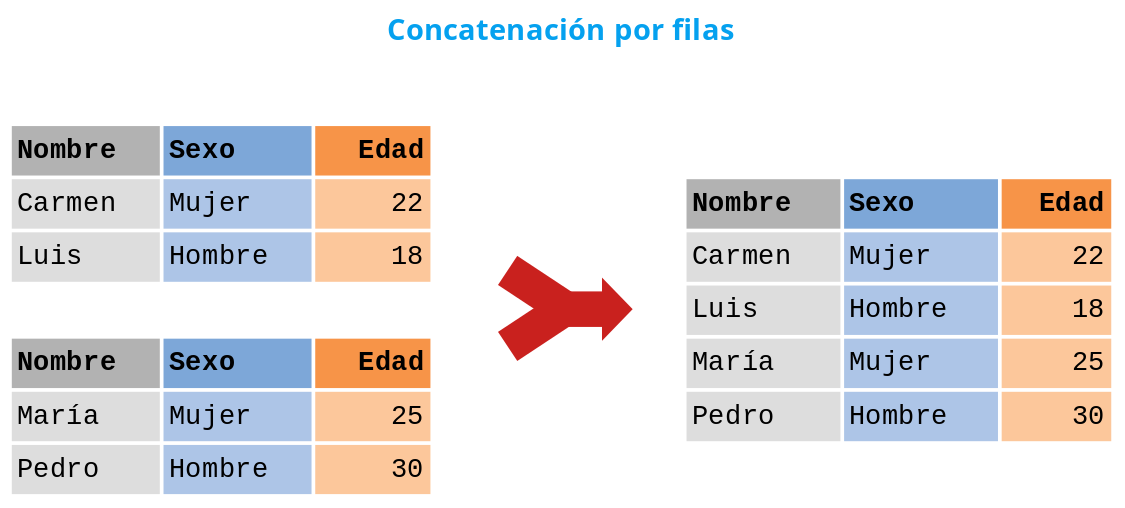
Figura 3.6, Concatenación de DataFrames por filas¶
Concatenación de columnas. Las columnas de los DataFrames se concatenan unas a continuación de las otras para formar el nuevo DataFrame. Para ello es necesario que los DataFrames que se combinen tengan el mismo índice de filas.
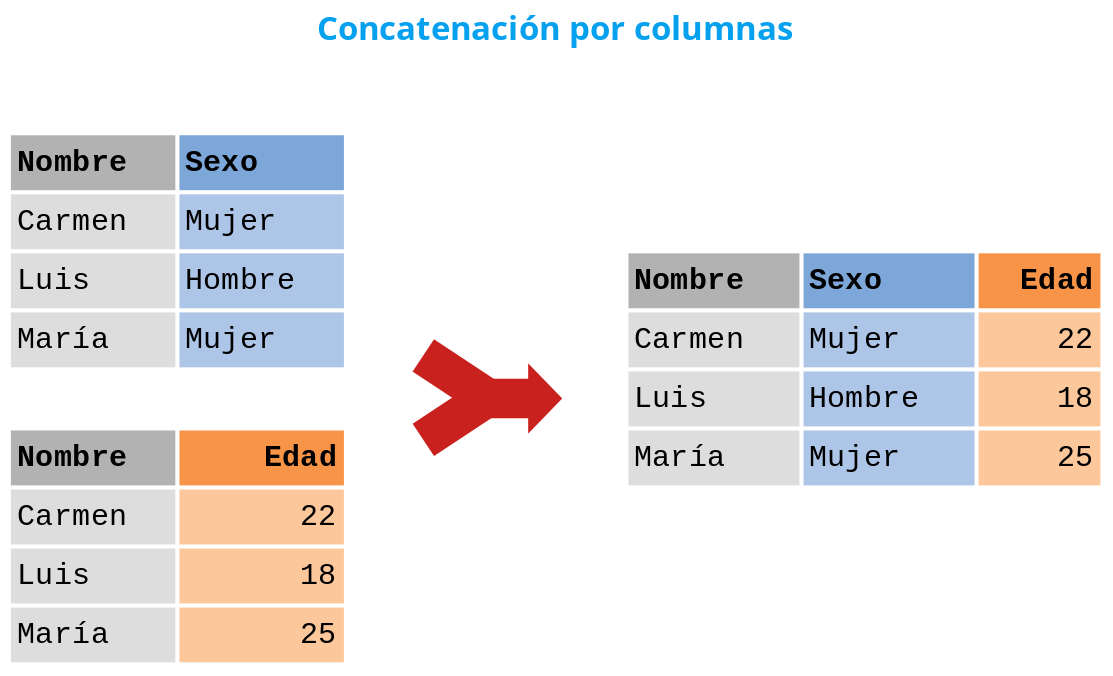
Figura 3.7, Concatenación de DataFrames por columnas¶
Para concatenar dos o más DataFrames se utiliza el siguiente método:
df.concat(dataframes, axis = eje): Devuelve el DataFrame que resulta de concatenar los DataFrames de la listadataframes. Siejees 0 (valor por defecto) la concatenación se realiza por filas, y siejees 1 se realiza por columnas.
Si los DataFrames que se concatenan por filas no tienen el mismo índice
de columnas, el DataFrame resultante incluirá todas las columnas existentes
en los DataFrames y rellenará con valores NaN los datos no disponibles.
Si los DataFrames que se concatenan por columnas no tienen el mismo índice
de filas, el DataFrame resultante incluirá todas las filas existentes en los
DataFrames y rellenará con valores NaN los datos no disponibles.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
3.1.25.2. Mezcla de DataFrames¶
La mezcla de DataFrames permite integrar filas de dos DataFrames que contienen información en común en una o varias columnas o índices que se conocen como clave.
Para mezclar dos DataFrames se utiliza el siguiente método:
df.merge(df1, df2, on = clave, how = tipo): Devuelve el DataFrame que resulta de mezclar el DataFramedf2con el DataFramedf1, usando como claves las columnas de la listaclavey siguiendo el método de mezcla indicado portipo.
El tipo de mezcla puede ser
"inner"(por defecto): El DataFrame resultante solo contiene las filas cuyos valores en la clave están en los dos DataFrames. Es equivalente a la intersección de conjuntos.1 2 3 4 5 6 7 8 9 10
>>> import pandas as pd >>> df1 = pd.DataFrame( ... {"Nombre": ["Carmen", "Luis", "María"], "Sexo": ["Mujer", "Hombre", "Mujer"]} ... ) >>> df2 = pd.DataFrame({"Nombre": ["María", "Pedro", "Luis"], "Edad": [25, 30, 18]}) >>> df = pd.merge(df1, df2, on="Nombre") >>> print(df) Nombre Sexo Edad 0 Luis Hombre 18 1 María Mujer 25"outer": El DataFrame resultante contiene todas las filas de los dos DataFrames. Si una fila de un DataFrame no puede emparejarse con otra los mismos valores en la clave en el otro DataFrame, la fila se añade igualmente al DataFrame resultante rellenando las columnas del otro DataFrame con el valorNaN. Es equivalente a la unión de conjuntos.1 2 3 4 5 6 7 8 9 10 11 12
>>> import pandas as pd >>> df1 = pd.DataFrame( ... {"Nombre": ["Carmen", "Luis", "María"], "Sexo": ["Mujer", "Hombre", "Mujer"]} ... ) >>> df2 = pd.DataFrame({"Nombre": ["María", "Pedro", "Luis"], "Edad": [25, 30, 18]}) >>> df = pd.merge(df1, df2, on="Nombre", how="outer") >>> print(df) Nombre Sexo Edad 0 Carmen Mujer NaN 1 Luis Hombre 18.0 2 María Mujer 25.0 3 Pedro NaN 30.0"left": El DataFrame resultante contiene todas las filas del primer DataFrame y descarta las filas del segundo DataFrame que no pueden emparejarse con alguna fila del primer DataFrame a través de la clave.1 2 3 4 5 6 7 8 9 10 11
>>> import pandas as pd >>> df1 = pd.DataFrame( ... {"Nombre": ["Carmen", "Luis", "María"], "Sexo": ["Mujer", "Hombre", "Mujer"]} ... ) >>> df2 = pd.DataFrame({"Nombre": ["María", "Pedro", "Luis"], "Edad": [25, 30, 18]}) >>> df = pd.merge(df1, df2, on="Nombre", how="left") >>> print(df) Nombre Sexo Edad 0 Carmen Mujer NaN 1 Luis Hombre 18.0 2 María Mujer 25.0"right": El DataFrame resultante contiene todas las filas del segundo DataFrame y descarta las filas del primer DataFrame que no pueden emparejarse con alguna fila del segundo DataFrame a través de la clave.1 2 3 4 5 6 7 8 9 10 11
>>> import pandas as pd >>> df1 = pd.DataFrame( ... {"Nombre": ["Carmen", "Luis", "María"], "Sexo": ["Mujer", "Hombre", "Mujer"]} ... ) >>> df2 = pd.DataFrame({"Nombre": ["María", "Pedro", "Luis"], "Edad": [25, 30, 18]}) >>> df = pd.merge(df1, df2, on="Nombre", how="right") >>> print(df) Nombre Sexo Edad 0 María Mujer 25 1 Pedro NaN 30 2 Luis Hombre 18
Por hacer
TODO Terminar de escribir esta sección.
Ver también
Consulte la sección de lecturas suplementarias del entrenamiento para ampliar su conocimiento en esta temática.
¿Cómo puedo ayudar?
¡Mi soporte está aquí para ayudar!
Mi horario de oficina es de lunes a sábado, de 9 AM a 5 PM. UTM - Madrid, España.
La hora aquí es actualmente 7:35 PM UTM.
Mi objetivo es responder a todos los mensajes dentro de un día hábil.
